To start thinking about Hyperon as a scoring engine, we first need to understand the concepts of a credit score, a scoring model, creditworthiness and a FICO score.
When a borrower comes to a lender, the institution (bank or credit card company) must evaluate their creditworthiness. Depending on available customer data, such as payment history or credit types, the lender will decide: to offer a loan or not. If there is a significant risk that the borrower will fail to make the required payments, the lender should deny the application. A borrower’s credit score is simply a numerical expression of their creditworthiness. A credit score can be used for various financial transactions, such as mortgages, private loans, credit cards or car loans.
Simply put, a scoring model is a mathematical model that takes many input variables (the customer’s data) and converts them all to a single score that represents the customer’s creditworthiness. The higher the score, the more likely the borrower will pay their bills. Scoring models often come in the form of numerous decision tables that compute partial scores, which are then weighted and added together.
A FICO score, introduced by the Fair Isaac Corporation, is one of the most widespread scoring models. There are many different versions for particular market segments (e.g. automotive lending or mortgages). Even if the exact structure of the FICO model is secret, some components are widely known, such as payment history, current debt, length of credit history, types of credit used or recent loan searches.
Now that we have defined the basic scoring concepts, let’s look at how Hyperon can be used to implement various scoring models.
Hyperon is a Business Rules Management System focused on performance. It is designed to easily handle large decision tables. The Hyperon engine uses in-memory indices and a carefully designed matching algorithm to search large decision tables (1M rows and more)in a few microseconds. Moreover, Hyperon offers a scripting language that allows users to write short functions that expand the capabilities of decision tables.Both software developers and operational staff can modify such functions or tables without touching the application’s code. The changes are immediately reflected in any application that uses the Hyperon engine.
Suppose we have a scoring model that defines a credit score as the weighted sum of partial scores (metrics) for different categories:
Each score is a number from 0 to 100. These components evaluate different aspects of the customer’s data, for example:
Our sample model uses customer data which implements the following object model:
To warm up a little, we’ll start by implementing the simplest indicator – s5, which depends only on the number of loan requests in the last 6 months. This can be achieved by using Hyperon’s most basic concept, called a parameter. Hyperon uses parameters as decision tables to produce outcomes based on the input.
The following is an example of s5 expressed as a parameter:
In other words, based on the customer’s data or context, the s5 parameter will produce the proper outcome. This parameter can be interpreted as follows:
All parameters in Hyperon come in the form of decision tables. They define condition columns and the outcome or multiple outcomes. We’ll get back to this in a moment.
Let’s take s6 as the second example. This indicator depends on the number of active credit accounts. The collection customer.credits contains all client’s credits, both active and closed, so we will use a Hyperon function to find the number of active ones.
The following is an example function named util.credits.countActive:
This sample function is implemented in the Groovy programming language. It takes all credits from the customer’s data, iterates all of them and counts only those that have the “active” property set to true.
As Groovy is a very expressive language, the same function can be written with far fewer keystrokes:
Once we have a dedicated function that counts active credits, we can create a parameter or decision table that takes this function’s result as an input. The following table is an example of s6 parameter.
As you can see, the previously defined function – named util.credits.countActive – is bound to the condition column which means that Hyperon engine will call this function and get its return value to find the final outcome. For example, if function returns 5, then the outcome of s6 parameter will be 92.
If we need to make s6 indicator dependent on two or more conditions, all we have to do is add more input columns to decision table, as in the following example:
To build any solution in Hyperon we can use parameters defined in the form of decision tables and functions written in a scripting language. Now let’s take a closer look at these core concepts.
Each input column (condition) takes a value from some source. There are two types of sources:
Each condition column has a defined matcher, which is used to check whether the input value matches to a condition. Hyperon comes with many useful matchers:equals, between, in, not-in, regex, like, contains/all, contains/any, etc.
On the other hand, each output column holds a potential parameter’s value. This potential value will become the outcome if all conditions in the same row evaluate to true.
Hyperon parameters can return a single value, several values (a vector) or even a matrix of values. In combination with different matchers, different matching modes and input sources, it is quite a powerful tool in a developer’s hands.
The following screenshot presents a real-life example of a parameter defined in Hyperon Studio.
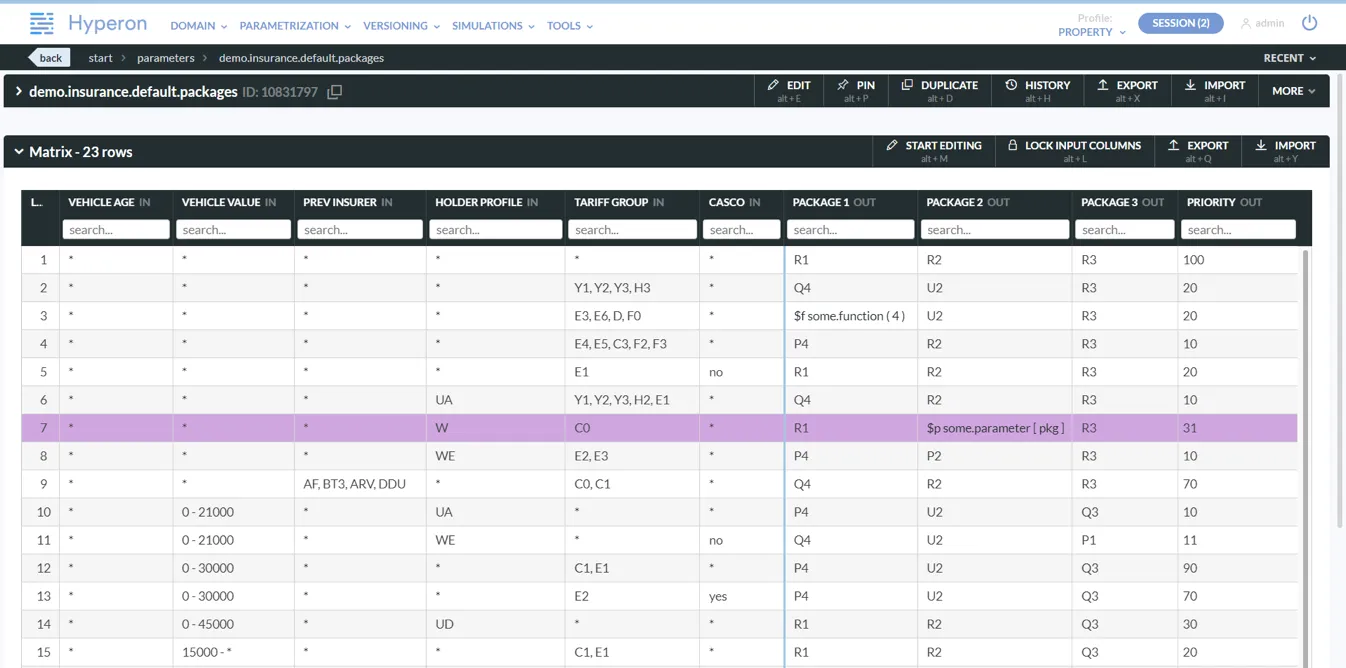
On the above screenshot you can see a parameter that has 6 conditions and 4 outcomes.Conditions include age and value of the vehicle (between matcher), name of the previous insurer (in matcher) and the insurer’s profile code (default matcher). The Hyperon rules engine will find the best matching row and return its 4 output values.
Typically, all Hyperon parameters are fetched from a database and converted into an in-memory index when used for the first time. The in-memory index allows matching rows to be found in a few microseconds. The index structure guarantees O(1) lookups if all conditions use default matchers.
It is not uncommon to see a project with more than 500 parameters (decision tables), with many having more than 100k rows, and some larger than 1 million rows.
Although Hyperon decision tables are a very powerful means to express business logic, sometimes this may not be enough. For such situations Hyperon offers a scripting language. In other words, developers or business users can write functions that behave exactly the same as a decision table does – they consume certain inputs and produce an outcome.
Users can write functions in Groovy or JavaScript (whichever they prefer) with help of the Hyperon standard library. The functions let them implement any business logic they want.
The following is an example of a Groovy-based function:
Hyperon functions can read domain models, evaluate parameters or call other functions. They can perform any logic dependent on domain model data. Hyperon functions come with a standard library in the form of predefined objects that enable developers to:
The following screenshot presents a real-life function edited in Hyperon Studio.
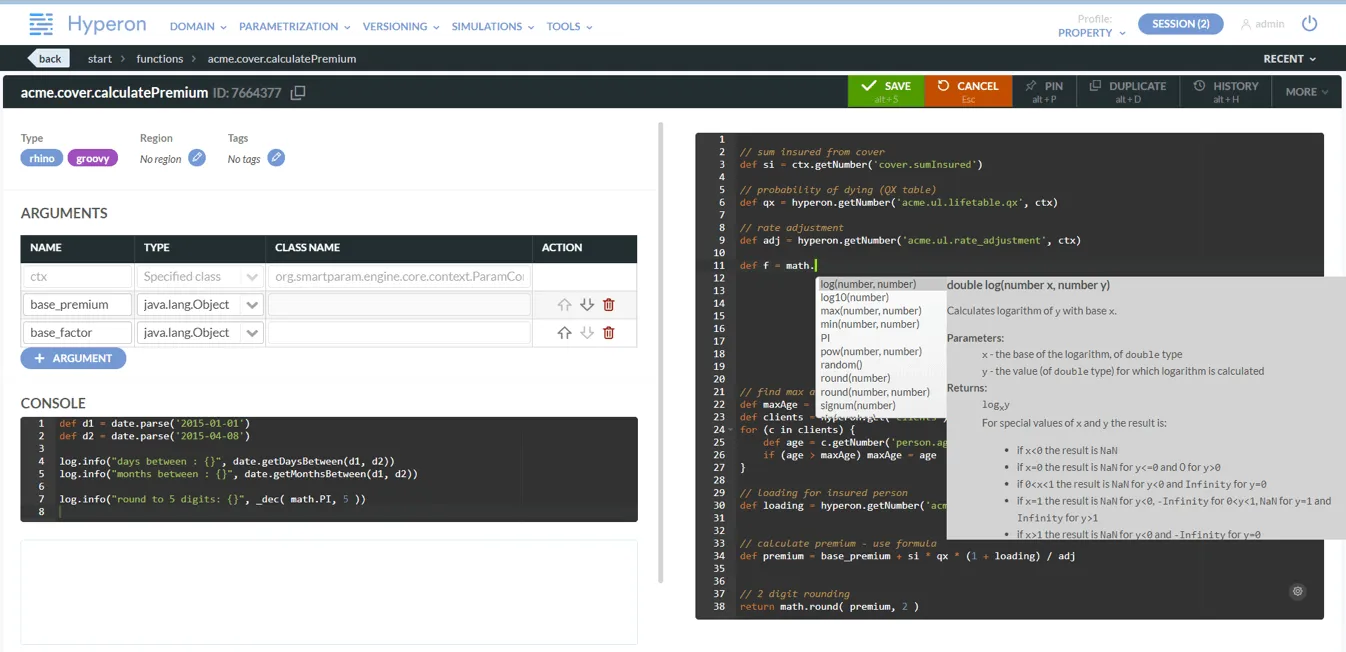
Functions and parameters together form a coherent ecosystem:
Let’s see how this can be leveraged:
The above parameter:
Many projects developed for the insurance or finance industries have proven that Hyperon parameters and functions together can handle any business logic.
Hyperon enables developers to externalize complex business logic. This logic (for example scoring rules) can be modified by developers or business experts in the Hyperon Studio UI. Each modification is immediately reflected in any application that uses Hyperon Runtime library, so we can say users may modify logic on the fly.
That makes Hyperon the best fit for rules-heavy projects, often found in the finance and insurance industries.








If you’re a programmer who is not afraid to get her or his hands dirty with the code, you can download special demo related to this use case:
Higson is a parameters engine you can configure to use it as a
Check how your company could benefit from Higson: development cost decrease, shorter time to market, easy maintance, elastic architecture and much more!
These are their success stories






